Statistical analysis
 image from unstats.un.org
image from unstats.un.org
Statistical Analysis is used to calculate mean and standard deviation, t-Test, and correlation between data sets. We do not cover this as a specific unit, however, the information will be incorporated into our curriculum as well your Internal Assessments. This information has been modified from the old IB Biology curriculum.
Key Terms
|
mean data set
correlation uncertainties |
standard deviation
significance cormorants chi-square |
error bars
significant number degree of freedom r value |
causation
correlation p value probability |
t-test
variable range |
Class Materials:
Error Analysis
Significant Figures
Precision Measurements and Uncertainties
Precision Lab
Topic 1 Statistics (ppt)
Biostatistics Practical Problems
Graphing In Edexcel
Graphing in Edexcel Practice problems
Standard Deviation (ppt)
Standard Deviation (notes)
Standard Deviation Practice problems
Hydroponics Standard Deviation Practice problems
t-Test (ppt)
t-Test (notes)
Correlation and Causation (ppt)
Correlation and Causation (notes)
Correlation reading
Correlations of cancer (pdf)
Data set #1 (pdf)
Data set #2 (pdf)
Data set #3 (pdf)
T-test reading
T-Testing in Biology University of
Statistics Review
Useful Links
Review of means
Click here for calculating SD with tools
Click here for Flash Card questions on Statistical Analysis
Click here for tips on Excel graphing.
“Using error bars in experimental Biology” by Geoff Cumming, Fiona Fidler, and David L. Vaux. (Journal of Cell Biology)
Are two sets of data really different?Click here to perform Student’s t-test
Click here to perform Student’s t-test via copy and paste
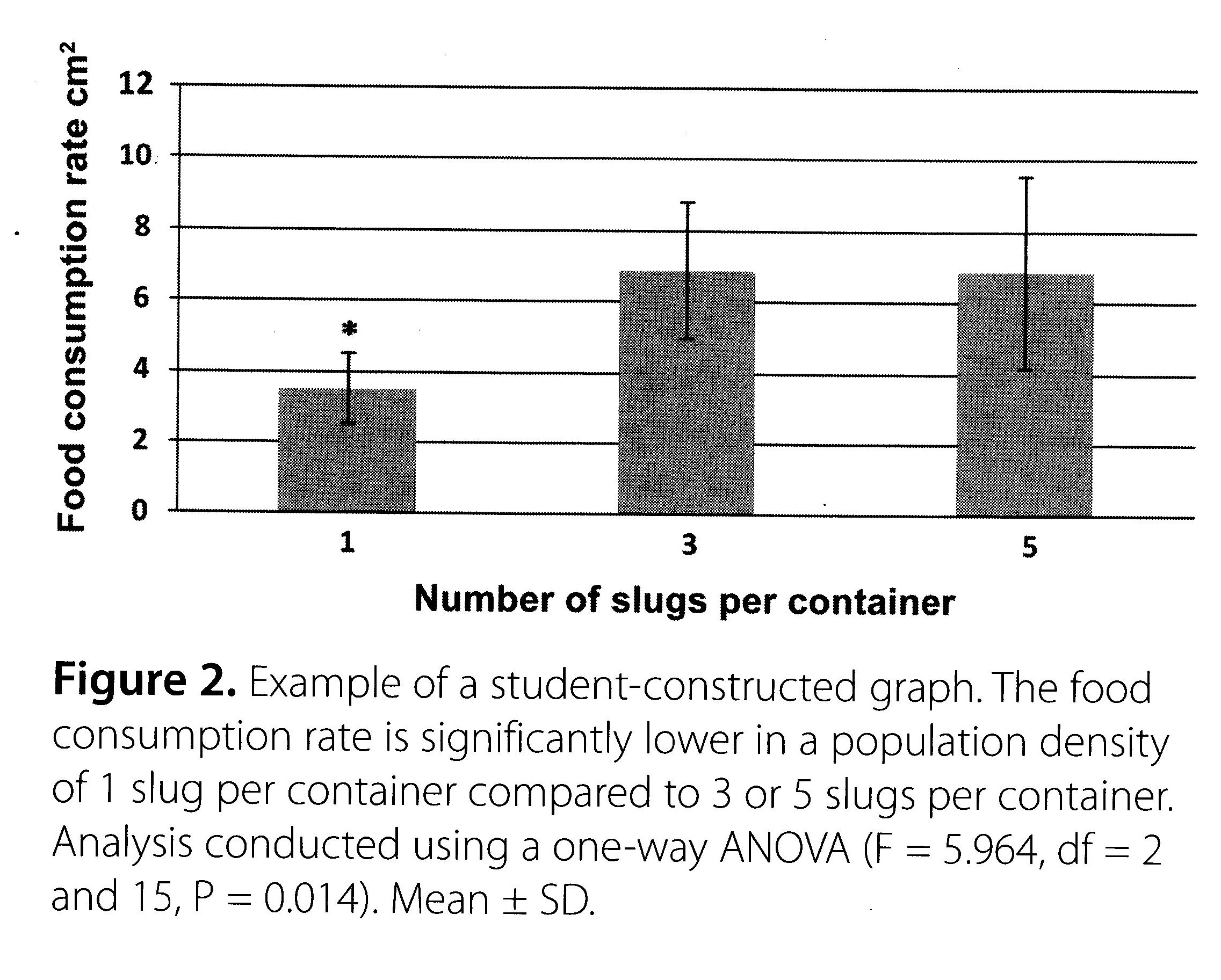
Example graph (from The Biology Teacher, September 2013)
Graphic Calculator Tour
Easy Calculation
Statistics calculator
MERLIN software for Excel
Chi-square calculator
Chi-square table
T-test calculator
Standard deviation reading
T-Test Table, Excel and calculations can be found here.
There are many statistical tools to establish a statistically significant correlation. read more here or read an article about Cause and Correlation by Wisegeek here.
Difference Between Correlation and Causation article
Excellent Handbook of Biological Statistics from John MacDonald
Basic Statistical Tools, from the Natural Resources Management Department
And The Little Handbook of Statistical Practice is very useful.
Sumanas statistics animations
Field Studies Council stats page, including the t-test
Open Door Website stats page and help with graphs and tables.
Making Population Pyramids on Excel
Spreadsheet Data Analysis Tutortial
Video over Table
Making Table g
Making Tables
This is an ecocolumn design you can use in the long-term IA’s 1 - from learner.org
Here’s another ecocolumn design you can use for the long-term IA project - from fastplants.org
What Statistical Analysis Should I Use
Error Analysis
Significant Figures
Precision Measurements and Uncertainties
Precision Lab
Topic 1 Statistics (ppt)
Biostatistics Practical Problems
Graphing In Edexcel
Graphing in Edexcel Practice problems
Standard Deviation (ppt)
Standard Deviation (notes)
Standard Deviation Practice problems
Hydroponics Standard Deviation Practice problems
t-Test (ppt)
t-Test (notes)
Correlation and Causation (ppt)
Correlation and Causation (notes)
Correlation reading
Correlations of cancer (pdf)
Data set #1 (pdf)
Data set #2 (pdf)
Data set #3 (pdf)
T-test reading
T-Testing in Biology University of
Statistics Review
Useful Links
Review of means
Click here for calculating SD with tools
Click here for Flash Card questions on Statistical Analysis
Click here for tips on Excel graphing.
“Using error bars in experimental Biology” by Geoff Cumming, Fiona Fidler, and David L. Vaux. (Journal of Cell Biology)
Are two sets of data really different?Click here to perform Student’s t-test
Click here to perform Student’s t-test via copy and paste
Example graph (from The Biology Teacher, September 2013)
Graphic Calculator Tour
Easy Calculation
Statistics calculator
MERLIN software for Excel
Chi-square calculator
Chi-square table
T-test calculator
Standard deviation reading
T-Test Table, Excel and calculations can be found here.
There are many statistical tools to establish a statistically significant correlation. read more here or read an article about Cause and Correlation by Wisegeek here.
Difference Between Correlation and Causation article
Excellent Handbook of Biological Statistics from John MacDonald
Basic Statistical Tools, from the Natural Resources Management Department
And The Little Handbook of Statistical Practice is very useful.
Sumanas statistics animations
Field Studies Council stats page, including the t-test
Open Door Website stats page and help with graphs and tables.
Making Population Pyramids on Excel
Spreadsheet Data Analysis Tutortial
Video over Table
Making Table g
Making Tables
This is an ecocolumn design you can use in the long-term IA’s 1 - from learner.org
Here’s another ecocolumn design you can use for the long-term IA project - from fastplants.org
What Statistical Analysis Should I Use
In The News:
Ed Yong writes for Cancer Research UK on the WHO’s verdict on mobile phones and cancer. Correlation vs cause!
Epidemiology: The Science of Cohort Studies. How do we generate lifetimes’ worth of data in studies in medicine? Ben Goldacre’s BBC Radio 4 documentary, Science: From Cradle to Grave. An amazing discipline to work in, and one birth cohort study has been running for over 65 years!
Click here for a funny article on the 9 circles of scientific hell.
Video Clips
Ed Yong writes for Cancer Research UK on the WHO’s verdict on mobile phones and cancer. Correlation vs cause!
Epidemiology: The Science of Cohort Studies. How do we generate lifetimes’ worth of data in studies in medicine? Ben Goldacre’s BBC Radio 4 documentary, Science: From Cradle to Grave. An amazing discipline to work in, and one birth cohort study has been running for over 65 years!
Click here for a funny article on the 9 circles of scientific hell.
Video Clips
Here is a really good video on Error Analysis
Stephanie Castle demonstrates in this Baccalaureate Biology Tutorial how to Calculate the mean and standard deviation of a set of values using a graphic calculator
Paul Andersen introduces science for the science classroom. He starts with a brief description of Big Data and why it is important that we prepare future scientists to deal intelligently with large amounts of data. He explains the difference between the population and the sample set. He briefly addresses the concepts of sample size, mean, media, range and degrees of freedom.
In this video Paul Andersen explains the importance of standard deviation. He starts with a discussion of normal distribution and how the standard deviation measures the average distance from the mean, or the "spread" of data. He then shows you how to calculate standard deviation by hand using the formula. He finally shows you how to calculate the standard deviation using a spreadsheet.
Paul Andersen shows you how to calculate the standard error of a data set. He starts by explaining the purpose of standard error in representing the precision of the data. The standard error is based on the standard deviation and the sample size. He works a problem and gives the viewer a problem to work on their own.
In this video Paul Andersen explains how to run the student's t-test on a set of data. He starts by explaining conceptually how a t-value can be used to determine the statistical difference between two samples. He then shows you how to use a t-test to test the null hypothesis. He finally gives you a separate data set that can be used to practice running the test.
Paul Andersen shows you how to calculate the ch-squared value to test your null hypothesis. He explains the importance of the critical value and defines the degrees of freedom. He also leaves you with a problem related to the animal behavior lab. This analysis is required in the IB Biology classroom
Paul Andersen explains how graphs are used to visually display data that is collected in experimentation. He describes five main types of graphs; line graph, scatter plot, bar graph, histogram and pie chart. He describes the important elements of a successful graph including labeled axis, title, data and a line of fit.
Paul Andersen shows you how to create a scatter plot with a best fit line in Microsoft Excel.
Paul Andersen shows you how to graph data by hand. He explains the required elements of a scatter plot with a best fit line. He shows you how to properly scale and label the axes.
Watch Hans Rosling’s brilliant Joy of Statistics here. For a short clip:

{kind=link}